

Cosa (non) misura il Quoziente Intellettivo
Cosa (non) misura il Quoziente Intellettivo

Nell’ultimo articolo abbiamo visto come sono nati i moderni test di intelligenza, e abbiamo iniziato a capire che significato dare a un punteggio di QI (quoziente intellettivo).
Per riassumere, il QI è un punteggio che ha significato statistico e che mette in relazione un individuo con una popolazione di riferimento. Il significato esatto del punteggio dipende dalla distribuzione utilizzata dal singolo test, che di solito è una gaussiana con media 100 e deviazione standard 15.
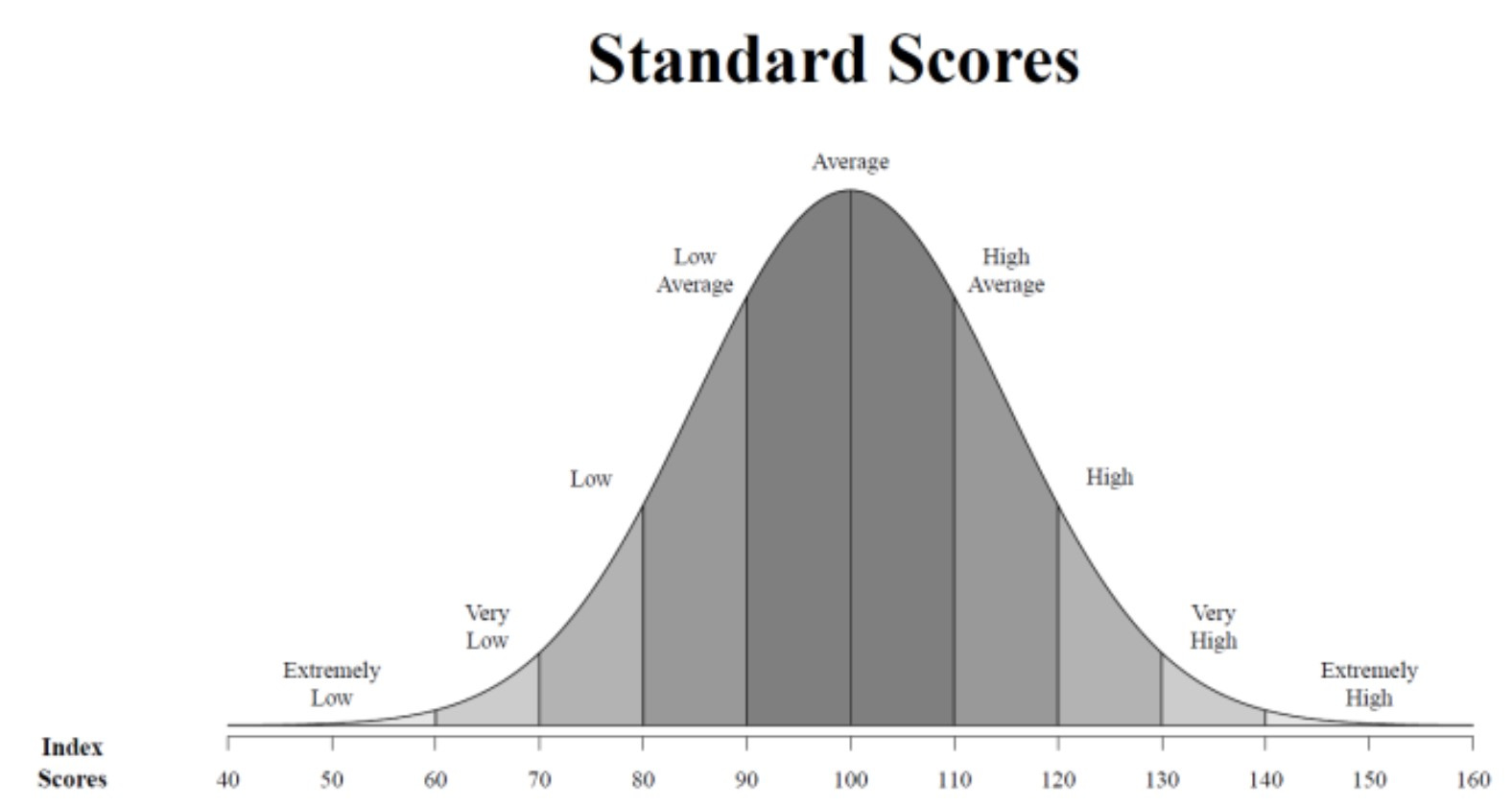
Per rendere il tutto concreto immaginiamo un gruppo di 1000 persone prese a caso fra tutti i cittadini italiani. Se somministrassimo loro un moderno test del QI ci dovremmo aspettare più o meno:
999 persone con un QI superiore a 55
977 persone con un QI superiore a 70
841 persone con un QI superiore a 85
500 persone con un QI superiore a 100 (che è il punteggio medio).
159 persone con un QI superiore a 115
23 persone con un QI superiore a 130
una persona con un QI superiore a 145
Statisticamente i punteggi sotto a 55 e sopra a 145 sono troppo rari per emergere su un campione casuale di sole mille persone. Basta guardare il grafico qui sopra per avere un’idea della loro rarità. La maggioranza delle persone hanno punteggi compresi fra 70 e 130 (circa 950 persone su 1000).
Dovrebbe essere tutto abbastanza chiaro, ma questa è solo una descrizione matematica. A noi interessa sapere come questi numeri siano connessi con ciò che comunemente intendiamo quando parliamo di “intelligenza”. Con questo articolo muoviamo i primi passi per capire cosa misura effettivamente un test del QI1.
Intelligenza relativa vs intelligenza assoluta
Prima di tutto ha senso toglierci ogni dubbio sul fatto che i test del QI attuali misurano solo le prestazioni relative fra individui, non le prestazioni assolute. Per capire concretamente cosa significa facciamo un esempio di misura assoluta.
Immaginiamo di voler misurare l’altezza di un gruppo di persone. Sappiamo che esiste una grandezza fisica chiamata lunghezza, che si misura in metri, e che possiamo misurare la lunghezza di un oggetto confrontandolo con una scala graduata (un righello ad esempio). Questo permette di assegnare un chiaro significato fisico a ciò che misuriamo, e di mettere in relazione lineare due lunghezze diverse: ad esempio 4 metri è il doppio di 2 metri. Siccome l’altezza è una lunghezza, possiamo misurare direttamente l’altezza di una persona, e assegnarle un numero. Possiamo quindi dire frasi come “Eloisa è alta 1,69 metri” e “Luigi è alto il doppio di sua figlia Anna”.
Se l’intelligenza fosse una grandezza fisica analoga alla lunghezza allora potremmo assegnarle una unità di misura (ipotizziamo si chiami neuro). Potremmo avere un “righello” per l’intelligenza e potremmo dire frasi come “Eloisa è intelligente 638 neuri” e “Michela è intelligente 800 neuri e Mariangela solo 400 neuri, quindi Michela è intelligente il doppio di Mariangela”.
Ma tutto ciò, allo stato attuale, non lo possiamo fare. Non abbiamo nessuna teoria condivisa che ci permette di trattare l’intelligenza come una grandezza fisica. L’unica cosa che possiamo fare è misurare le prestazioni sui singoli test, ordinandole secondo una scala di rarità con una distribuzione statistica che ci fa comodo (ovvero la distribuzione gaussiana, che è la curva a campana che emerge in molti fenomeni naturali come appunto l’altezza, e che ha interessanti proprietà matematiche).
Se fosse così anche per l’altezza la situazione sarebbe alquanto bizzarra. Immaginatevi che i righelli non esistano, e che per valutare l’altezza utilizzassimo un “quoziente d’altezza” che indica solo la nostra posizione relativa rispetto alle altezze della popolazione, in modo analogo al QI. Con questo metodo potremmo dire:
l’italiano medio è più alto del 50% degli italiani (quoziente d’altezza 100);
Patroclo è più alto del 9% degli italiani (quoziente d’altezza 80);
Achille è più alto del 99,997% degli italiani (quoziente d’altezza 160).
Ma questo non ci direbbe nulla su quanto effettivamente siano alti Patroclo e Achille, e nemmeno quanto è alto l’italiano medio! Possiamo chiaramente vedere che Patroclo è più basso della media e Achille più alto, ma non sappiamo di quanto. Per quanto ne sappiamo Achille potrebbe essere alto 60 chilometri, oppure 20 millimetri. Non avremmo strumenti (righelli) per dirlo.
Quando si parla dei punteggi di QI bisogna sempre tenere a mente questo aspetto. I punteggi di QI sono solo un modo comodo per esprimere la posizione relativa di un punteggio rispetto ad altri. Questo significa che chi ha 160 di QI non ha un’intelligenza doppia di chi ha 80. È solo in una diversa posizione sulla gaussiana, che dà solo informazioni statistiche (es. 160 è un punteggio superiore a quello del 99,997% delle persone). Ma quanto è più intelligente chi ha 160 rispetto alla media? Mille volte? Tre volte? Il 10%? Non abbiamo alcun modo per dirlo.
O forse sì?
La validità dei test
Non c’è nessuna autorità che valuta test cognitivi mettendo loro il bollino di “test di intelligenza”. Molti test considerati dai ricercatori discrete misure d’intelligenza sono chiamati in altri modi dai loro creatori (un esempio è il SAT, Scholastic Aptitude Test). E molti test online denominati “test di intelligenza” in realtà non hanno alcuna validità empirica che giustifichi questo nome.
Ma come facciamo a distinguere test “che funzionano” da test che sono solo giochini senza alcun impatto pratico? E cosa significa che un test “funziona”?
Per capirlo bisogna introdurre il concetto di validità. Un test è considerato valido se riesce a misurare davvero ciò che vuole misurare. E siccome in psicometria è difficile avere misure dirette di validità (non abbiamo righelli per l’intelligenza!) bisogna cercare gli effetti di ciò che consideriamo intelligenza nella vita reale al di fuori del test.
Quindi in sostanza un test di intelligenza è considerato valido se ha buone correlazioni con effetti dell’intelligenza nel mondo reale, e se ci permette di fare previsioni ragionevoli. Per fare un esempio, se ci si aspetta che in media una persona intelligente impari più in fretta di un’altra meno intelligente, ci aspettiamo correlazioni rilevanti fra i risultati dei test e le performance legate all’apprendimento (titolo di studio, voti scolastici, etc). E a partire dal risultato di un test del QI valido ci aspettiamo di poter prevedere (in senso statistico, non deterministico) che risultati verranno ottenuti in quei domini in cui l’apprendimento è rilevante.
Ovviamente ciò che ci si aspetta dall’intelligenza non è oggettivo: dipende dalle teorie che abbiamo sull’intelligenza umana. Teorie diverse possono portare ad aspettative diverse, e a cercare effetti diversi.
In ogni caso c’è un discreto accordo fra i ricercatori su alcuni effetti da considerare rilevanti, e i test considerati validi tendono ad avere ottime correlazioni (secondo standard psicometrici) con risultati nel mondo reale. Approfondiremo sia le teorie sia le correlazioni empiriche in articoli futuri.
Come assaggio, qui sotto trovate un paio di grafici che illustrano correlazioni interessanti.
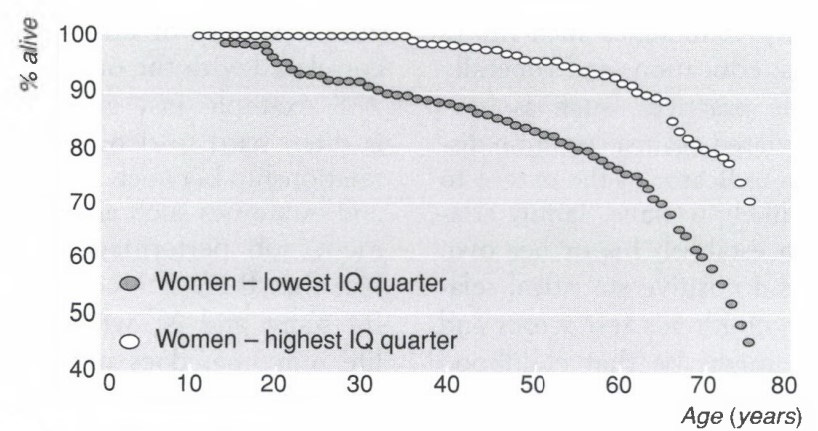
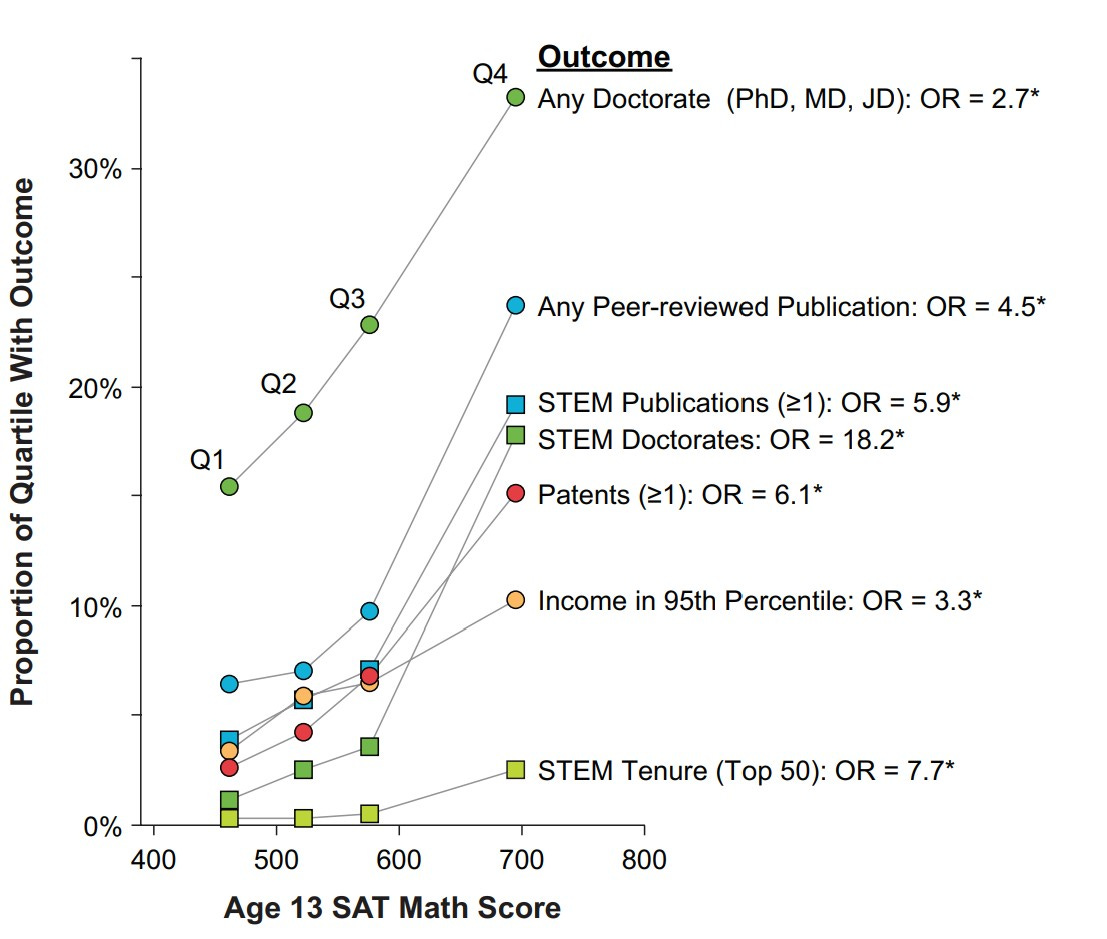
Bisogna fare molta attenzione a interpretare questo tipo di correlazioni, che sono sempre di tipo probabilistico. In particolare la direzione di causalità non è sempre ovvia (quindi dire che “il QI causa X” è spesso fuorviante o errato) e molte variabili rilevanti sono invisibili a un primo sguardo (ad esempio una correlazione tra QI e X può essere dovuta a una variabile nascosta Y che è correlata sia a QI sia a X).
E come nota a margine: la validità non è l’unico criterio per valutare un test. I test devono anche essere normati su un campione rappresentativo della popolazione di riferimento, devono essere “affidabili” (nel senso che se la stessa persona fa due versioni dello stesso test deve ottenere risultati ragionevolmente simili), e devono idealmente avere buone correlazioni con costrutti teorici legati ai modelli di intelligenza su cui si basano (ad esempio il fattore di intelligenza generale g, che approfondiremo in futuro).
La scelta degli item nei test
Usare la validità di un test permette di poter costruire ottimi test con item apparentemente “piovuti dal cielo” e scorrelati da qualsiasi attività umana che intuitivamente consideriamo intelligente. Questo credo sia uno dei punti che lascia perplesse molte persone ostili ai test del QI. Com’è possibile che “questo stupido puzzle” misuri la mia intelligenza? È ridicolo!
Per fare un esempio: il senso comune ci dice che schiacciare un tasto il più velocemente possibile non è una prova di chissà quale intelligenza. Ma, se si scoprisse che prestazioni in un test di velocità nello schiacciare un tasto fossero fortemente correlate con risultati accademici e lavorativi e con altri validi test di ragionamento più complessi (o con costrutti teorici come g), può aver senso considerare quel test come una misura di intelligenza (o perlomeno di un sottoinsieme dell’intelligenza).
Ovviamente è utile accompagnare questo modo di scegliere gli item con una visione teorica che a priori ci guida su quali abilità vogliamo valutare e quali ha senso escludere, soprattutto per misure più complete (ovvero che valutano abilità considerate differenti dalla teoria di riferimento).
Un altro criterio che guida la scelta degli item in un test è la sua capacità di distinguere e ordinare le prestazioni di individui diversi. Come abbiamo detto i test di intelligenza sono costruiti per misurare differenze fra persone, quindi i test sono costruiti per massimizzare queste differenze. Se una specifica abilità, per quanto meravigliosa e “intelligente”, è posseduta in modo quasi identico da tutti gli esseri umani, di solito è lasciata fuori dai test. Questo non significa che quell’abilità sia irrilevante per l’intelligenza in senso ampio. Significa solo che le differenze fra persone sono troppo piccole o difficili da misurare.
Infine è desiderabile per un buon test avere due proprietà.
Gli item devono essere ordinabili per difficoltà, calcolata in termini di quante persone risolvono il singolo item. Ad esempio se il problema X viene risolto dal 10% delle persone e il problema Y è risolto dal 40% delle persone, X è più difficile di Y.
Se X è l’item più difficile risolto da una persona, quella stessa persona deve aver risolto tutti gli item più facili di X.
In pratica queste proprietà ideali non vengono mai raggiunte perfettamente. È sempre possibile che un soggetto risolva correttamente un problema molto difficile e ne sbagli uno più facile. Ma molti test sono costruiti cercando rendere questa eventualità improbabile.
Abilità non misurate dai test
Per quanto molti moderni test del QI siano piuttosto ampi nel tipo di abilità misurate (spesso sono batterie di una decina o più di subtest che spaziano dal vocabolario a ragionamento astratto, memoria uditiva, aritmetica e velocità nel compiere task semplici) è pur vero che per limiti di tempo, spazio e formato non possano misurare tutto. Alcune abilità teoricamente rilevanti vengono lasciate sistematicamente fuori.
Il problema principale è che risulta troppo difficile o poco pratico valutare quella specifica abilità nel contesto di un test di intelligenza.
Alcuni esempi rilevanti sono i seguenti.
Abilità cognitive rilevanti nelle interazioni sociali. Rispondere in modo intelligente alla domanda “cosa faresti in questa situazione?” è diverso dall’agire in modo intelligente nella corrispettiva situazione reale. Oltretutto interpretare quale sia il comportamento più intelligente in un contesto sociale dipende molto dalla cultura di riferimento e da fattori esterni all’intelligenza.
Creatività. Esistono alcuni test che valutano la produzione originale in breve tempo (un esempio noto è "elenca quanti più modi possibili di usare un mattone”). Tuttavia è difficile valutare in un setting limitato la creatività in senso più ampio (quella che associamo alla scrittura di romanzi o ideazione di nuove teorie scientifiche), che richiede molto tempo e risorse per essere sviscerata.
Capacità di apprendimento. Il problema è simile alla creatività. Per valutare direttamente la capacità di apprendere è necessario seguire una persona nel corso del tempo, il che è poco pratico. E all’interno dei test di intelligenza si cerca di solito di limitare la quantità di apprendimento pregresso necessario per risolvere gli item (per differenziare l’essere colti dall’essere intelligenti). Non è sempre così: alcuni test di intelligenza cristallizzata (costrutto che approfondiremo in futuro) misurano in quale grado si sono assorbite informazioni nel corso della vita. Tuttavia l’apprendimento autodiretto e specializzato è diverso dall’assorbire informazioni generali sull’ambiente circostante.
Razionalità. La razionalità è un costrutto in grossa parte sovrapposto all’intelligenza misurata con i tradizionali test del QI. Tuttavia alcuni aspetti non vengono misurati. Si pensi alla capacità di mettere in discussione il proprio sistema di valori, di riconoscere fallacie e bias, di porsi obiettivi e di organizzare le proprie risorse per risolvere problemi di ampio respiro (che per non stanno all’interno di un test standard). Ci sono tentativi di creare “test di razionalità” (si veda il lavoro di Stanovich) ma attualmente è un’area abbastanza trascurata dai test del QI.
Abilità legate a movimenti nello spazio. Danzare, giocare a Tetris o guidare una bicicletta sono attività che necessitano la capacità di elaborare informazioni spaziali in movimento. La valutazione diretta di queste abilità è spesso inesistente nei test del QI, che sono solitamente svolti in un contesto chiuso e con “carta e penna” (o simili varianti digitali), che porta a valutare le capacità di elaborazione visuo spaziale in un contesto statico, non dinamico.
A mio avviso i problemi legati alla valutazione di queste abilità, per quanto reali, sono comunque limitati. Alcune di queste abilità vengono già parzialmente misurate (parte della razionalità ad esempio è già misurabile in termini di QI, anche se non in modo del tutto soddisfacente), e gli attuali test del QI mostrano buone correlazioni con risultati tangibili che ci aspetteremmo da queste abilità (ad esempio la capacità di apprendimento). Tuttavia è vero che c’è abbondante spazio per rendere i test di intelligenza più completi. Come già detto il limite è più pratico che teorico (un test che dura 10 ore avrebbe altre conseguenze, come l’aumentata influenza di stanchezza e calo di motivazione), soprattutto considerando che anche test piuttosto brevi e semplici si sono mostrati empiricamente piuttosto simili (come validità) a test più completi, complessi e di lunga durata.
Nei prossimi articoli esploreremo più in dettaglio le principali teorie sull’intelligenza umana e cercherò di rispondere ad alcune delle domande più frequenti.